고정 헤더 영역
상세 컨텐츠
본문

반응형
※ CISA 시험 공부하면서 요약 정리한 것으로 일부 중복된 내용 또는 오류가 있을 수 있습니다.
1. IT 기술 및 관리
1-1. 하드웨어 도입
■ 하드웨어 도입 (Hardware Acquisition)
- 하드웨어의 구입을 위해서는 필요한 업무 사이즈를 정리하고, 이를 근거로 구입하게 될 H/W, S/W의 용량을 산정하며, 최종적으로 제안서 선정 기준을 작성하여 벤더에게 배포하게 된다.
- 이때 사양서 및 업체 평가 기준은 **제안 요청서 (RFP : Request for Proposal) 또는 입찰 요청서 (ITT : Invitation to Render)의 형태로 공급자에게 전달되며, 이를 제안서 작성 시 참조하게 된다.
■ Vendor 제안서 평가 기준의 고려사항
- 응답 시간 (Response Time) : 사용자가 명령을 내린 ㅎ후 결과가 나올 때까지의 소요시간, 보통 온라인 작업에 적용
- 작업 종료 시간(OR 처리 시간) (Turnaround Time) : 로그-인 시점으로부터 헬프 데스크나 벤더가 문제를 직시하는 데 걸리는 시간. 또는 배치 환경에서의 응답 시간
- 시스템 반응 시간 (System Reaction Time) : 운영체제가 어떻게 정보를 처리하는지를 평가 → 작업 처리 속도에 대한 성과치
- 처리량 (Throughput) : 단위 시간 동안 시스템에 의해 처리될 수 있는 작업량으로 효율성 및 성능 척도
- 작업 부하 (Workload) : 벤더의 시스템이 주어진 시간 동안 처리할 수 있는 작업량, 요구되는 작업량을 다루는 능력
- 호환성 (Compatibility) : 타 시스템과의 호환성, 개방성
- 용량 (Capacity) : CPU, Memory, HDD…..
- 네트워크로부터의 많은 동시 요청을 다루기 위한 새로운 시스템의 용량
- 이용도 (Utilzation) : 시스템의 평균 이용률
- 가용성 (Availability) : 시스템 운영 시간 대비 시스템 다운 타임
■ IS 감사인이 해야 할 일
- 도입 과정이 비즈니스 필요에 의해 시작되었으며, 이러한 필요에 대한 하드웨어 요구사항이 명세서에 반영되었는지를 판단한다.
- 여러 공급업체가 고려되었는지, 그리고 그들 간의 비교가 앞에서 열거한 기준에 따라 수행되었는지를 판단한다.
1-2. 하드웨어 유지보수 계획
■ 유지보수 계획에 포함되어야 할 요소
- 일상적으로 유지보수가 필요한 각각의 하드웨어 자원을 위한 평판이 좋은 업체 정보
- 유지보수 일정, 비용
- 유지보수 실행 이력 → 계획된 것과 예외적인 것 모두를 포함해야 한다.
■ IS 감사인의 확인 사항
- 공식적인 유지보수 계획이 작성되고 관리자에 의해 승인되었는지 확인한다.
- 유지보수 비용이 예산을 초과하거나 과도하지 않은지 확인한다.
- 유지보수 비용이 과도하다는 것은 유지보수 절차를 충실히 따르지 않았거나 하드웨어가 노후해 곧 교체해야 함을 가리키는 것일 수 있다.
- 그러므로 적절한 조사와 후속 조치가 필요하다.
■ IS 관리자 임무
- 유지보수의 이행 여부는 물론 공급업체의 유지보수 명세서와 어긋남이 없는지를 감시, 식별, 문서화해야 한다.
1-3. 하드웨어 모니터링 절차
■ 하드웨어 오류 보고서 (H/W Error Report)
- CPU, 입출력, 전원, 기억 장치의 장애를 알려준다.
■ 가용도 보고서 (Availability Report)
- 사용자 만족도 척도
- 컴퓨터 가동시간, 사용자, 다른 프로세스 이용 가능 시간
- 정보시스템 과도한 정지 시간 (down time)이 존재하는지가 가장 중요하다.
- ※ Down Time (정지 시간)은 부적절한 하드웨어 시설, 지나친 운영체제의 유지 관리, 예방 정비 (preventive maintenance)의 부족, 전원 공급기, 온도 조절 장치 등의 부적절한 물리적 설비나 운영 훈련의 부족을 암시
■ 이용도 보고서 (Utilization Report)
- 자원 활용도 척도
- 처리 부하를 예측할 때, 정보시스템 관리자가 사용한다.
- 다중 사용자 환경에서 자원 이용도를 평균 85% ~ 95% 범위이다.
- 하드웨어 이용 추세 정보를 통해 자원 요구 사항을 예측한다.
- 기기, 주변 장치의 이용 정도를 기록한다.
- 감시 소프트웨어의 이용 정도를 기록한다.
- ※ 이용도가 일상적으로 95% 수준 이상이면 IS 관리자는 여유 공간을 확보하기 위해 사용자 및 응용 시스템 패턴을 검토하고 컴퓨터 하드웨어를 업그레이드하며, 그리고 또는 비핵심적인 처리를 제거하거나 별로 중요하지 않은 처리를 수요가 적은 시간대 (야간과 같은)로 옮기는 등의 비용 절감이 가능한 방안을 모색을 고려해야 한다.
- ※ 만일 이용도가 일상적으로 85% 이하라면 하드웨어가 처리 요구사항에 비해 과도한 것이 아닌지 따져 볼 필요가 있다.
1-4. 시스템 인터페이스
■ 정의
- 하나의 애플리케이션의 출력이 다른 어플리케이션의 입력으로 전달되는 과정에서 사람이 전혀 또는 극히 일부의 개입만 필요한 인터페이스
■ 종류
- System to system I/F : Analytics, Data Mining 등 특정 결과 또는 데이터 추출을 위하여 사용됨
- Partner to partner I/F : 합의된 시스템 사이의 지속적인 데이터 전송
- Person to person I/F : 사람을 통한 데이터 전송 - Email 또는 Offline 방식의 데이터 전달 → 관리 및 관리 측면, 보안 및 통제 측면의 취약점이 존재
■ 보안 이슈
- 시스템 인터페이스의 오동작에 기인한 부정확한 관리 보고서
- 사업 또는 의사결정 과정에 심각한 부정적 영향 미침
- 작은 오류일지라도 잠재적인 법적 준수 위반을 야기시킬 수 있음
- 대응
- 중앙 집중화된 추적 및 관리기법, 문서, 정부 규정에 따른 감사증적 확보 필요
- 암호화, 강력한 접근통제 및 인증, 수신자 검증 절차
- 자동화된 로그
2. 데이터 거버넌스 및 시스템 성능 관리
2-1. Data 거버넌스
■ 개요
- EA : Enterprise Architecture
- 데이터 품질 - 품질 기준 : 고유성 (Intrinsic), 연관성/관련성 (Contexual), 보안/접근성 (Security/Accessibility)
- 개요
- 배경 : 지속적인 데이터의 변경은 관리 및 유지보수를 점점 더 복잡하게 함
- Data 형태 : 텍스트, 숫자, 그래픽/비디오 등 기업 운영의 책심적인 요소로 발전함
- 데이터 거버넌스의 보장
- 사업 목적 달성을 위한 이해관계자 요구사항들이 평가됨
- 우선순위 식별 및 의사결정 과정을 통해 데이터/정보 관리 방향이 정립
- 상호 협의된 방향과 목표에 대한 성과 모니터링
■ 데이터 수명 주기
- 계획 (Plan), 설계 (Design), 생성/획득 (Build/Acquire), 사용/운용 (Use/Operate)
- 모니터 (Monitor), 배치 (Dispose, 폐기)
■ 감사인의 역할
- 조직의 사업 목적에 부합하도록 지원
- 표준을 사용하여 처리되는지 확인
- 정보자산들이 사업목적과 일관성 있게 구성되었는지 확인
2-2. 시스템 소프트웨어의 구입 시 고려사항
■ 시스템 소프트웨어의 최종 결정 시 고려사항
- 요구되는 컴퓨터 환경에 대한 제안된 S/W의 적합성
- 기존의 전산 환경과의 통합성
- Hard & Soft Costs
- 처리 업무, 기능적이고 기술적인 요구와 사양
- 비용/효과
- 노후화 가능성
- 기존 시스템과의 호환성
- 보안
- 기존 관리자들에게 요구되는 사항
- 훈련과 신규 채용의 필요성
- 향후의 필요성 증가 여부
- 시스템 성능과 네트워크에 대한 영향
2-3. 매개변수
■ 소프트웨어 통제기능 혹은 매개변수 (Parameters)
- 시스템의 성능을 적절하게 조절한다.
- 시스템 동작 기록 (activity log)과 같은 기능을 구동시킨다.
- 시스템의 동작 방식과 물리적 구성, 업무 부하(workload)에 따른 상호 작용 등을 결정한다.
- 매개변수의 선택은 조직의 작업 부하와 통제 환경의 구조에 적합하여야 한다.
- 운영체제 내부에서 통제가 이루어지는 방법을 알 수 있는 가장 효과적인 방법은 “소프트웨어 통제 기능과 매개변수를 검토”하는 것이다.
■ 소프트웨어 무결성을 위한 운영체제의 기능
- 의도적이거나 부주의한 변경에서 운영체제 보호한다.
- 사용자 프로그램이 특별한 권한을 가지고 수행되는 프로그램을 간섭할 수 없음을 보장한다.
- 다음 사항을 보장하기 위한 효율적인 프로세스 격리 (isolation)를 제공한다.
- 시스템과 데이터의 무결성을 유지하기 위해서는 운영 환경과 부여된 권한을 정확하고 일관성 있게 정의, 통제 및 감시하는 것이 필요하다.
- 운영체제의 무결성을 평가하기 위해서 감사인은 시스템 통제 선택사항과 시스템 디렉터리에서 발견할 수 있는 매개변수를 검토해야 한다.
2-4. 작업 스케줄링 소프트웨어 & 시스템 유틸리티
■ 작업 스케줄링 소프트웨어
- 일시에 대규모의 배치 작업을 처리할 때 사용된다.
- 일일 처리 일정을 준비하고 어떤 작업을 준비하고 시작해야 할지를 자동적으로 결정해 준다.
- 작업 정보가 한 번에 준비되므로 오류 가능성이 감소한다.
- 운영자에 대한 의존도가 감소된다.
- 작업의 의존관계가 정의되므로 하나의 작업이 실패할 경우 그 작업 결과에 의존하는 다른 작업들은 처리되지 않는다.
- IT 자원의 효과적인 사용이 가능하다.
- 컴퓨터 자원의 이용을 최적화하는 데 사용된다.
- 모든 작업의 성공/실패에 대한 기록을 관리한다.
■ 유틸리티 프로그램
- 응용의 정상적인 처리와 시스템의 안정적인 운영을 위해 필요한 일상적인 작업을 수행하는 시스템 소프트웨어
- 보안 시스템 외부에서 실행될 수 있으며 활동의 감사 증적을 남기지 않고도 사용이 가능하기 때문에 사용 제한을 위한 강력한 통제 절차의 마련이 필요하다.
2-5. 소프트웨어 라이센스 관련 이슈
■ IS 감사인의 역할
- S/W 저작권 침해 상황을 미연에 방지하거나 이를 적발한다.
- S/W의 비 인가된 사용이나 복사에 대비하는 문서화된 정책과 절차를 검토한다.
- 필요시 승인, 동의 없이 복사본을 만들지 않겠다는 동의서에 서명하는 것이 의무화인지 검토한다.
- 모든 표준 응용과 라이센스가 있는 시스템 소프트웨어 목록을 검토한다.
■ 라이센스 지불 유형
- CPU
- Seat
- 동시 사용자 단위 : 사전에 정해진 시간 주기 동안의 사용자 수
- 이용도 : CPU의 동작시간 또는 동시에 활성화되어 있는 사용자 수
- Workstation : 해당 SW에 접속해 있는 Workstation 수
- 전사적 (Enterprise) : Site 라이센스
■ 소프트웨어 라이센스 침해 예방을 위한 선택 사항
- 소프트웨어에 자산 관리 프로세스 도입
- 소프트웨어에 대한 통제를 중앙 집중화하고 배포와 설치를 자동화한다 (사용자가 소프트웨어를 설치할 수 없도록 막는 것도 포함)
- 모든 PC는 일정 수준 제한되어야 함 (USB, Disk Drive 등)
- S/W에 대한 통제를 중앙 집중화하고 분배화 설치를 자동화한다.
- 모든 PC의 디스크를 없애고, 안전한 LAN에서 Application에 접근토록 한다.
- LAN에 Metering (요금 별납) S/W를 설치하고, 모든 PC가 이것을 통하여 응용 S/W에 접근하도록 한다.
- 사용자의 PC를 정기적으로 LAN을 통해서나 직접적으로 검색해서 허가받지 않은 복사본은 PC에 설치되지 않도록 한다.
2-6. 소스코드 관리
■ 개요
- 소스코드에 대한 접근은 응용프로그램 또는 공급자와의 계약조건에 따라 다름
- 소스코드 없을 경우 Escrow 계약을 활용하는 것은 중요함
- 외부 도입 vs 직접 개발에 따라 다른 정책 필요
- 내부개발의 경우 SDLC (Software Development Life Cycle : 소프트웨어 개발 수명 주기)에 준하여 적용되며 변경관리, 배포관리, 품질보증 및 정보보안 관리 단계와 연관되어 관리되어야 한다.
■ VCS (Version Control System : 버전 관리 시스템) / RCS (Revision Control System : 개정 관리 시스템) 관련 용어
- Repository (저장소)
- Check Out / Check In
- Synchronization (동기화)
- Branch (분기)
■ VCS (Version Control System : 버전 관리 시스템) 사용 시 장점
- 접근통제, 변경 내용 추적, 공동(동시) 개발, 이전 버전으로의 롤백 가능, 분리 가능
■ 최종사용자 컴퓨팅
- 컴퓨터 소프트웨어 제품을 활용하여 최종 사용자가 자신의 정보 시스템을 설계/구현하는 것을 의미한다.
- 장점
- 응용 시스템의 빠른 구축 및 확산 → IT 부서 지원을 감소시키지만 IT 부서 지원 부족은 위험을 증가시킴
- 단점
- 에러가 있을 수 있으며 이로 인해 부정확한 결과가 산출될 수 있음
- 변경관리 및 배포관리를 벗어난 다른 버전의 소프트웨어가 생산됨
- 보안성 결여 및 백업 미 생성
3. 운영관리, SLA 및 데이터 관리
3-1. ITIL (IT Infrastructure Library) 요약
■ 지원 : 유지보수, 6요소
- 회사의 어떤 Application (예:ERP)을 처음 도입하여 사용하다 문제 발생 하는 경우, 문제해결과정을 머릿속에 그려보세요.
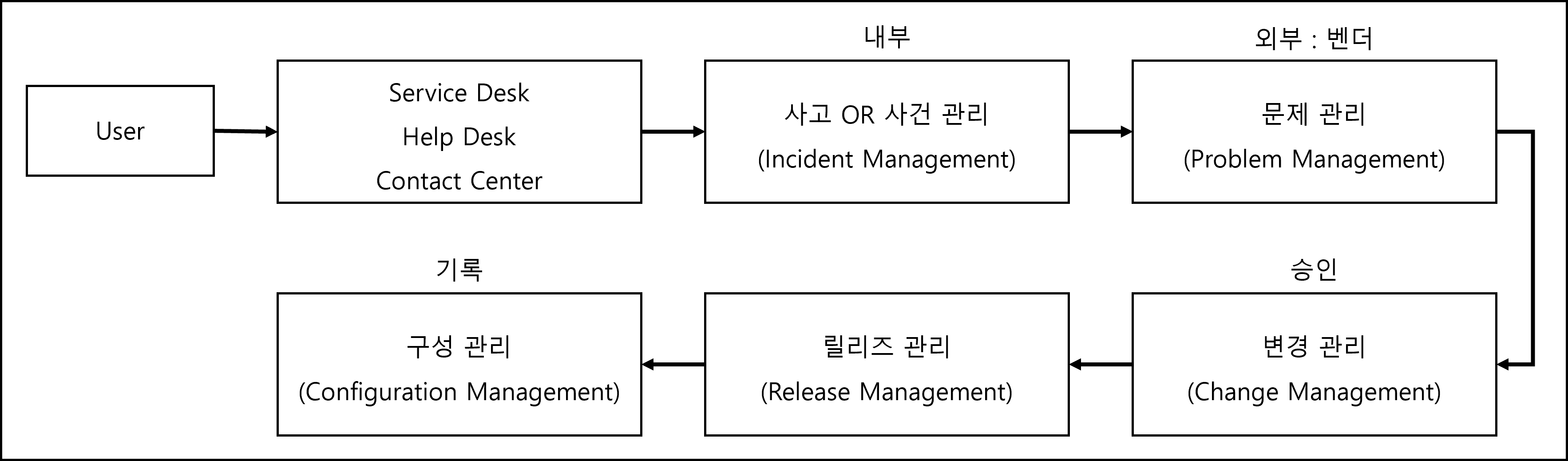
■ 전달 : 운영, 5요소

3-2. SLA (Service Level Agreement : 서비스 수준 협약(계약))
■ 개요
- IT 조직과 고객과의 계약
- 제공되는 서비스를 구체적으로 명시함
- 고객 관점에서 비기술적인 용어로 서술되며, 서비스를 조율하고 측정하는 데 사용된다.
- SLA Cycle : SLR (Service Level Requst : 서비스 수준 요구사항), SLA (Service Level Accept : 서비스 수준 수용), SLM(Service Level Management : 서비스 수준 관리), SIP (Service Level Implemnet Plan : 서비스 수준 향상 계획)이 반복되며 이는 지속적 개선을 위함이다.
■ 서비스의 효율성 및 효과성 모니터링 도구
- 예외보고서 (비정상 작업 종료 보고서)
- 사업 요구사항의 부족한 이해
- 응용프로그램에 대한 설계, 개발 또는 시럼단계에서의 부족함
- 부적절한 운영 지침과 운영 지원
- 부적절한 작업순서
- 부적절한 시스템 구성 (System Configuration)
- 부적절한 용량계획 (Capacity planning)
- 시스템 또는 응용프로그램 로그 (자동화된 분석 도구 지원)
- 승인받은 프로그램 또는 IT 직원으로 제한된 민감한 데이터로의 접근
- 승인된 목적을 위한 Softwore Utility의 사용 (복잡성으로 인한 수작업 어려움)
- 승인된 프로그램만 실행되며, 비승인된 프로그램 실행 방지
- 정확 안 데이터 생산과 적절한 보호
- 운영자 문제점 보고서 (수작업 유지 관리)
- 운영자 작업 일정표 (수작업 유지 관리)
■ 데이터베이스 통제
- 정규화, 체크포인트, 락킹 메커니즘, DB 재조직
- 데이터 무결성 : 개체 무결성, 참조 무결성, 의미상 무결성
4. 사업 연속성 계획
4-1. 업무 연속성 계획 (BCP : Business Continuity Plan)
■ 정의
- 조직 생존에 필요한 핵심 기능 및 운영의 예기치 못한 중단으로 인해 발생하는 조직의 사업 위험을 절감하기 위한 계획
- 핵심 기능의 원상복구를 위한 포괄적 계획
- 단일 계획으로 통합될 필요는 없으나 상호 일관성이 있어야 한다.
- 운영의 연속성 (Continuity of Operation) : 핵심 업무 기능의 연속성
- 재난 복구 계획 (Disaster Recovery Plan) : 핵심 IT 자원의 연속성
- 업무 복구 (또는 재개) 계획 (Business Recovery ( or Resumption) Plan) : 완전 성상화
■ BCP (업무 연속성 계획)와 DRP (재해 복구 계획)의 공통점
- 일부 예방적 기능이 있으나, 교정통제로 분류된다.
- 위험을 회피하는 것이 아니라, 위험을 수용한다.
- 가용성 확보가 그 목적이다 (예 : 성능 신뢰성, 기능 일관성, 처리 연속성)
- 잔여위험을 대상으로 계획을 작성한다.
- 조직에서는 대외비로 관리한다.
■ 역할 구분
- 이사진 (Members of BOD) : 프로젝트의 개시, 최종 승인 및 지원
- 고위 경영진
- 업무 연속성에 대한 수립책임 및 궁극적 책임을 진다.
- 업무 연속성 계획 (BCP) 기획 프로세스와 재해 이후의 진두지휘한다.
- 복구 관련 시간 목표와 순서를 결정한다.
- 기능 관리진 및 일선 실무진 : 계획의 실행과 테스트에 참여한다.
- IS 감사인의 책임
- (벤더를 포함하여) 업무 연속성 계획의 적합성을 평가한다.
- 테스트 과정을 독립적인 입장에서 참관한다.
4-2. 가용성 관련 위협
■ Event (사건)
- Cause (원인)
- 자연적 원인 : 재해, 재앙 등
- 인위적 원인 : 고의적 사건, 해킹 등
- 기술적 원인 : 실수, 오작동 등
- Occurrence (발생)
- Interruption (방해) : 업무에 부정적 영향
- Incident (사고) : 보안에 부정적 영향
■ Condition (상황)
- Disruption (중단) : 정상활동에 제약 발생
- Non-disaster (비재해) : 아주 짧게 (예 : 실수, 오작동)
- Disaster (재해) : 보통 하루 이상 → 대체처리시설 활용
- Catastrophe (재앙) : 장기간 → 시설완전파괴 → 원설비복구 (예: 911, 대지진 등)
- Emergency (비상) : 긴급한 초기대응 필요 (예 : 인명대피)
- Contingency (돌발) : 특정 시스템 또는 특정 업무의 중단
- TIP) 사고 대응 (Incident Handling)의 우선순위
- 보안 사고인지에 대한 신속한 판단
- 인명 대피
- 피해 확산 방지
- 사업 연속성을 전제로 문제 해결
- 증거 수집 및 범위 수사
- ※ 최종 사용자들의 신속한 사고 신고가 필수적이다.
4-3. 업무 연속성 관련 상황
■ Disruption (중단)
- 정상적인 활동 수행 능력의 제약 상황
- 상당 기간 활동이 중단되는 상황이 재난 (disaster)이다.
- 정보시스템과 관련해서 중단은 다음과 같이 구분된다.
■ Incident (보안 침해 사고)
- 보안에 부정적 영향을 주는 예상치 못한 사건들. 정보시스템 관련해서는 다음과 같이 구분할 수도 있다.
- Crisis (위기) : 하루 이상의 중단이 예상되는 심각한 사고 (Critical incident)
- Major incident (중대 사고) : 최장 12 전후의 중단 발생이 가능한 사고
- Minor incident (작은 사고) : 1~2시간의 중단 발생이 가능한 사고
- Negligible incident (사소한 사고) : 중단 (Disruption)으로 이어지지 않는 사고
- TIP ) BCP (업무 연속성 계획) 평가 순서
- 개별 부서의 BCP (업무 연속성 계획) 적정성 평가
- 개별 부서 간의 BCP (업무 연속성 계획) 상호 일관성 평가
- 업무 포괄적 BCP (업무 연속성 계획)의 필요성 판단 및 비용 고려하여 BCP (업무 연속성 계획) 개발 권고
4-4. 업무 영향 분석 (또는 평가) (BIA : Business Impact Analysis)
■ 의의
- 업무 중단으로 인한 영향을 정성적/정량적으로 평가한다.
- 고위 경영진의 참여와 결정이 중요한 요소이다.
■ 관련 태스크
- 핵심 IT 자원의 식별
- 핵심 업무 프로세스를 식별한다.
- 핵심 업무 프로세스를 지원하는 핵심 IT 자원을 식별한다.
- 두절 (끊어짐)의 영향과 MTD (Maximum Tolerable Downtime : 최대 허용 정지시간) 식별
- 핵심 IT 자원의 두절로 인한 영향을 산정한다.
- 영향 분석을 기초로 최대 허용 정지시간 (MTD)를 식별
- IT 자원 요소의 MTD (최대 허용 정지시간) 중 가장 짧은 것이 시스템의 MTD (최대 허용 정지시간)이다.
- 복구 우선순위의 개발
- 시간 민감성 (Time Sensitivity)과 내성 (Tolerance, 수작업 대체 가능성)을 기준으로 북구 우선순위를 결정한다.
- 시간 민감성은 높고 내성은 낮을수록 복구 순위가 높아진다.
- RTO (Recovery Time Objective : 복구 목표 시간) 설정
- 피해 누적 속도를 고려하여 결정한다.
- 고위 경영진의 의지도 중요한 결정 요소이다.
- 복구 목표 시간 (RTO) ≤ 최대 허용 정지시간 (MTD)
■ 업무 영향 분석 (BIA) 수행
- 모든 업무 파악 → 핵심 기능 식별
- RPO (Recovery Point Objective : 복구 목표 시점), RTO (Recovery Time Objective : 복구 목표 시간 ), MTD (Maximum Tolerable Downtime : 최대 허용 정지시간) 결정 → 위험에 기반을 둔 복구 우선순위 결정
- 업무 영향 분석 (BIA) 단계에서는 사용자 및 고위경영진의 참여가 매우 중요하다. 만약 그렇지 않다면, 업무 영향 분석 (BIA) 실패 → 업무 연속성 계획 (BCP) 실패
4-5. 복구 관련 목표 수준
■ 복구 관련 시간대
- RPO (Recovery Point Objective : 복구 목표 시점)
- 복구되어야 하는 거래 처리 시점
- 다시 말해 (1) 중단 시 회귀해도 무방한 데이터베이스의 과거 이미지 (2) 용인할 수 있는 데이터 유실량
- 백업 주기 결정에 매우 중요한 지표이다. (즉, 백업주기는 복구 목표 시점 (RPO)를 초과해서는 안된다)
- 복구 목표 시점 (RPO)이 0이다 = 업무중단 없다 ≒ 미러링 방식 = 동기식 저장
- RTO (Recovery Time Objective : 복구 목표 시간)
- 업무 처리 능력을 복구하기 위한 목표 시점
- 복구 목표 시간 (RTO)는 고위 경영진이 결정한다.
- MTD (Maximum Tolerable Downtime : 최대 허용 정지시간)
- 조직이 업무 처리 중단으로 인한 영향을 감내할 수 있는 최대 시간
- 최대 허용 정지시간 (MTD)가 짧다 = 중요 자산이다 = 빠른 복구 필요 = 높은 비용
- 가장 짧은 최대 허용 정지시간 (MTD)은 시스템 MTD이다.
- MTO (Maximum Tolerable Outage : 최대 허용 가동중단)
- 이차 사이트에서 대체 처리할 수 있는 최대 시간
- 이차 사이트의 SDO (Service Delivery Objective : 서비스 제공 목표)가 낮을수록 MTO (최대 허용 가동중단)도 짧아진다.
4-6. BCP (Business Continuity Plan:업무 연속성 계획)&DRP (Disaster recovery plan:재해 복구 계획)
■ 테스트 접근법
| 종류 | 특징 |
| 체크리스트 | - 각각의 부서에서 BCP를 검토한다. - 체크리스트로 점검한다. |
| 구조적 워크스루 | - 각 기능의 대표자들이 회합한다. - 구조적 의사일정에 따른다. - 문서 테스트 방식으로 수행된다. - 가장 많이 사용되는 기법이다. |
| 모의실험 | - 이차 사이트 재배치까지만 테스트한다. - 이차 사이트에서의 실제 정보 처리는 없다. |
| 병행 테스트 | - 일차 및 이차 사이트에서 정보 처리한다. |
| 완전 중단 테스트 | - 일차 사이트에서 업무를 완전히 중단한다. - 이차 사이트에서 업무 처리한다. |
■ 테스트 및 유지보수 관련 유의사항
- BCP (Business Continuity Plan : 업무 연속성 계획) 정보의 적시성 검토가 관건이다.
- 사전 공지가 필수적으로 이루어져야 한다.
- 전문 직원은 물론 일반 직원들까지 참여해야 한다.
- 업무 폭주 시간대 (Peak Time) 또는 기간은 피하는 것이 좋다.
- 테스트 결과를 정성적 및 정량적으로 측정하고 평가해야 한다.
- 테스트 및 BCP (Business Continuity Plan : 업무 연속성 계획)의 갱신은 최소 1년에 1회 & 변화가 있을 때 수행해야 한다.
■ 준비성 테스트
- 분산된 지역
4-7. 사후 검토 및 계획의 갱신
■ 사후 검토
- Documentation of an Event (이벤트 문서화)
- Forensics : (필요시) 범죄 조사, 증거 수집 및 보존
- 사건에 대한 문서화 및 보고
- Post-Event Review (사후 검토)
- 원인 및 교정 조치의 식별
- 대응 절차 및 증거 등에 대한 분석
- 업무 연속성 계획의 갱신
- 업무 연속성 및 재해 복구 능력을 개선하기 위한 최선의 절차이다.
■ 복구 계획의 갱신
- 조직의 요구가 변하기 때문에 전략도 변화한다.
- 새로운 응용 시스템을 개발하거나 획득하면 복구 계획도 변경해야 한다.
- 사업 전략, 소프트웨어 및 하드웨어의 변화에 따라 중요한 응용 시스템도 대폭 변경되어야 한다.
- 환경과 핵심 장비의 변경, 관리 인력의 변화로 복구 계획 유지가 어려진다.
4-8. 테스트 및 유지보수 관련 감사인의 역할
■ 사업 연속성 계획 검토
- 내용의 최신성 및 최신 변화의 반영 여부를 판단한다.
- 고위 경영진의 참여와 승인 여부를 검토한다.
- 아웃소싱 환경에서는 특히 벤더의 협력도 필요하다.
■ 과거 테스트 결과 평가
- 재해 복구 계획의 효과성 평가에 있어 가장 필수적인 자료이다.
- 테스트 결과는 정성적으로는 물론 정량적으로도 평가해야 한다.
- 주기적 테스트 여부 및 테스트 권한 여부에 대해서 검토한다.
■ 오프사이트 저장소 평가
- 백업 절차 및 주기가 적정한지 판단한다.
- 매체에 대한 샘플링 조사를 통해 데이터의 최신성을 검증한다.
■ 핵심 인력 면담
- 역할의 숙지 여부 및 역할 분담의 적정성을 판단한다.
■ 오프사이트 시설의 보안 평가
- 오프사이트 시설의 호환성을 검증한다.
- 오프사이트 처리 시설의 보안 상태를 검토한다.
- 물리적 환경적 보안 수준은 일차 사이트와 동일해야 한다.
■ 대체 처리를 위한 계약 검토
- 계약 내용이 사업 요구사항을 충족하는지 판단한다.
■ 보험의 보상 범위 및 보험금의 충분성 검토
5. 재해 복구 계획
5-1. 대체처리 개념
■ 대체처리 개념

■ 사이트
- Primary Site (기본 사이트)
- Original Site : 재해 전부터 사용되던 일차 사이트
- New Home Site : 재해 후 새로 건설한 일차 사이트
- Secondary Site (이차 사이트)
- Alternative site (대체 사이트) : 일차 사이트 중단 시 임시 사용하는 사이트
- Interim Site (경우 사이트) : 일차 사이트로 이관하기 전에 경유하는 사이트
■ 관련 활동 구분
- Recovery (복구) : 재해로 영향을 받은 기능을 체계적 회복하는 과정
- Resumption (재개) : 복구 과정 중 특히 백업 사이트에서 핵심 기능 복구와 재시작
- Reconstitution (재구성) : 중단된 일차 사이트 기능 정상화 과정
- Reconstruction (재건) : 새로운 위치에서 일차 사이트 구축
- Restoration (복원) : 일차 사이트에서 기능 정상화 및 재시작
- Relocation/Migration (재배치/이동) : 타 사이트로의 이동
5-2. 이차 사이트 유형에 따른 장단점
■ 가용 속도에 따른 이차 사이트 구분
| 사이트 | 장점 | 단점 |
| Mirrored | - 일차 사이트와 구성 동일 - 데이터 동기화 가능 |
- 많은 구축 비용 - 평상 시 철저한 검토 |
| Hot | - 신속한 가용성 - 호환성 테스트 가능 |
- 미러드 사이트에 비해 데이터 복구 필요 |
| Warm | - 필요 시 핫 사이트로 전환 - 저렴한 구축 비용 |
- 시스템 확보 필요 - 하드웨어 벤더의 영향력 |
| Cold | - 유지 비용의 최소화 - 데이터 백업만 준비 |
- 가용화 시간이 긺 - 시스템 확보 필요 - 핵심 응용 테스트 제약 |
5-3. 상용 대체 사이트의 선택
■ 이차 사이트 구축 시 고려사항
- 일차 사이트와 동일한 자연재해의 노출 아래 있어서는 안 된다.
- 합리적 수준의 하드웨어/소프트웨어의 호환성이 보장되어야 한다.
- 일차 사이트와 동일한 수준의 물리적 접근 통제 및 논리적 접근 통제, 환경 통제가 확보되어야 한다.
- 자원 가용성에 대한 보증을 얻기 위하여 작업 부하에 대한 감사를 수행햐야 한다.
- 복구 대상 응용의 우선순위에 대한 합의가 있어야 한다.
- 물리적 통제 및 보안 등에 대한 주기적 테스트가 필요하다.
5-4. 재해 대응 과정

- IRP (Incident Response Plan : 사고 대응 계획)
- EAP (Emergency Action Plan : 긴급 조치 계획)
- CCP (Crisis Communication Plan : 위기 커뮤니케이션 계획) - 핵심 의사결정자 비상 연락망
- OEP (Occupant Emergency Plan : 거주자 비상 계획) - 인력 대피 계획
- COOP (Continuity of Operation Plan : 운영 연속성 계획)
- DRP (Disaster Recovery Plan : 재해 복구 계획)
- BRP (Business Recovery Plan : 업무 복구 계획)
■ 공지 및 가동 (Notification & Activation)
- 재해 공지 (Notification)
- 비상조치 (Emergency Action)
- 피해 평가 (Damage Assessment)
- 재해 복구를 준비하는 최초 단계이다.
- 재해 선언 (Declatation of Disaster)
- BCP (Business Continuity Plan : 업무 연속성 계획) 가동 (Activation)
■ 복구 (Recovery)
- 대체 사이트 (Backup site, Alternative site)의 구축 및 테스트
- 대체 사이트로의 재배치 (Relocation)
■ 재구성 (Reconstitution)
- 상세 피해 평가
- 일차 사이트의 복원 (Resumption) 또는 재구축 (Reconstruction)
- 일차 사이트의 테스트 및 일차 사이트로의 재배치 (Relocation)
- 재해 종료 선언
5-5. 연속성 확보 및 복구 관련 역할
■ 공지 및 가동 단계
- Emergency Action Team (비상대응팀) : 피해 확산 방지, 인명 구조와 초기 대응
- Assessment Team (평가팀) : 재해의 원인 및 피해 평가. 재해 발생 선언
■ 복구 단계
- Emergency Management Team (비상관리팀) : 재해 복구 감독 및 활동 조정
- Coordination Team (조정팀) : 지리적으로 분산된 현장에서 복구 노력 조정■ 재구성 단계
- Salvage Team (복원팀) : 상세 피해 평가, 회복 전략 수립, 이관 지휘 및 재해 종료 선언
- Relocation Team (재구축팀) : 일차 사이트로의 이관을 수행한다.
■ 재구성 단계
- Salvage Team (복원팀) : 상세 피해 평가, 회복 전략 수립, 이관 지휘 및 재해 종료 선언
- Relocation Team (재구축팀) : 일차 사이트로의 이관을 수행한다.
5-6. 전략적 복구 시간 목표
■ 전략적 복구 시간 목표

■ 복구 시간 목표의 결정
- 기능 중단으로 인해 핵심 업무 운영이 받게 되는 영향의 정도에 의거한다.
- 고위 경영진이 결정한다 → 중요한 고려 사항 : 비용
- 정지로 인한 비용과 복구에 소요되는 비용을 동시에 고려하여 결정한다.
■ 복구 시간 목표에 따른 시스템 구분
| 구분 | 수작업 대체 여부 | 시간 민감도 |
| Critical (핵심) | 불가 | 매우 높음 |
| Vital (중요) | 짧은 기간에 한함 | 높음 |
| Sensitive (민감) | 약간 장기간 가능 | 보통 |
| Non-Critical (비핵심) | 대체 가능 | 낮음 |
5-7. 오프사이트 저장소
■ 의의
- Offsite Storage (= Offsite Library, Offsite Vault)
- 일차 사이트와 동일한 재해에 노출되지 않는 안전한 장소에 데이터를 주기적으로 백업한다.
- 최신의 데이터와 문서 및 서식이 백업되어야 한다.
- Cf. 오프사이트 백업과 디스크 미러링은 대체 관계가 아니다.
■ 오프사이트 저장소 기록 관리
- 모든 백업 테이프에 대한 데이터 세트의 이름, 일련번호, 생성 일자, 회계 기간, 오프사이트 저장소에 등록된 일련번호
- 모든 중요 문서의 문서명, 위치, 관련 시스템 및 최종 갱신일
5-8. 서버의 이중화 및 데이터 백업 방식
■ 서버의 이중화
- Fail-Tolerant or Fault Tolerant 전략
- 장애 감내 또는 고장 감내
- 하드웨어 중복을 통해 장 시에도 기능이 지속된다.
- Mirroring Site
- 일차 사이트와 이차 사이트의 데이터를 실시간으로 동기화
- 높은 대역폭과 많은 비용이 소요된다.
- Load Balancing / Clustering
- L4 스위치 (하드웨어) 또는 클러스터 서버 (소프트웨어) 사용
- 업무를 분산하여 효율성 및 신뢰성을 제공한다.
■ 백업 방식
- Full Backup (전체 백업)
- 디스크상의 (선택한) 모든 파일들에 대한 백업
- 백업 매체 보관 및 통제가 용이하다.
- 많은 양의 테이프가 필요하며, 백업 수행 시간도 길다.
- Differential Backup (차등 백업)
- 최근 전체 백업 이후 변경된 파일만 백업
- 소요 시간은 증분 백업 시간과 전체 백업 시간 사이이다.
- Incremental Backup (증분 백업)
- 최근 모든 백업 이후 변경된 파일만 백업
- 저장 매체 활용이 효율적이며, 백업 시간도 절감된다.
- 복구 시 많은 저장 매체가 필요하다.
- 다양한 시점에서 복구를 할 수 있으므로, 빠른 재해 복구 기능이 있다.

반응형
'let's study > CISA' 카테고리의 다른 글
| [Domain 5] 정보자산의 보호 (요약) (4) | 2023.01.27 |
|---|---|
| [Domain 3] 정보시스템 구입, 개발 및 구현 (SDLC) (요약) (0) | 2023.01.27 |
| [Domain 2] IT 지배와 관리 (0) | 2023.01.27 |
| [Domain 1] IS 감사 프로세스 (0) | 2023.01.27 |
DarkSoul.StoryDarkSoul.Story 님의 블로그입니다.




